One of the architecture forums I'm active in has many "real architects" (those that create the built environment - buildings, parks, towns etc.) as well as I.T. Architects and a common discussion is why Architecture has a much higher "success" rate than I.T. Architecture.
By "success" we generally mean that whatever was originally designed gets built with few modifications from the original plan and once built lasts for quite a long time - at least for its initially projected life and usually much longer.
I.T. projects on the other hand as a success rate considerably below 50% (some studies put it below 20%) and even then the successful projects are subject to considerable change even before the first iteration goes into production.
Why is this?
Part of it that when a Building Architect designs a building he has access to almost everything he needs to know about all the materials present in his proposed building (stress and sheer factors, density, composition, life expectancy, degradation rates etc) and a set of scientific formulae for calculating everything else.
At the high-end of the industry Dynamic Simulation Models are used extensively in building design - one of the companies that I've dealt with is the Building Research Establishment Ltd who specialise in developing and publishing these simulation models for use by Building Architects - so before anything is physically built they are able to simulate many different building configurations before settling on a final design.
As a consequence a Building Architect is pretty certain (within whatever probability boundary they require) that the proposed building will be fit for purpose, meet all the legislative requirements and can be built from the desired materials.
IT Architects on the other hand, generally have to use "our experience" to guess at the best way of solving a problem and, because we have no scientific way of proving what will or will not work, must use powers of persuasion to convince people that the proposed solution will meet the requirements.
So, when we do try and research a particular subject we generally decide on a number of subjective "design patterns" that sort of provide a solution but no means of choosing between them. Consequently we end having to commit money and physically build significant parts of a target architecture before we can test that it works. That's a huge leap of faith for most organisations which is why the "power of persuasion" is so important - in many ways much more important than technical prowess (as I've found to my cost more than once in the past).
If we assume that accurate and provable prediction is a major part of why "real architecture" is so much more successful than "IT architecture" then the question becomes how to introduce simulation models into the IT world?
I worked on a resource simulation model once when I was at British Airways in the 1990's which they used it for modelling resource requirements across their flight network but it could have modelled pretty much any activity based environment - It's only limitation was the availability of the necessary base data to populate it with.
Shortly after than I also worked on another simulation application for the same company that focused on simulating, predicting and optimising Bookings demand across the flight network. (I mention this because it's exactly the same problem as modelling data-flows through an organisations data processing systems.) Again the only limitation was availability of base data and the more we had - we used 5 years of data in the end - the more accurate the simulations would be.
In both cases the business had a fully worked through model on which it could base any decisions with a reasonable chance of success prior to actually spending further time & money.
The major part of the solution is then to build appropriate, industry accepted simulation models that can use the metrics to forward project onto a proposed IT architecture and allow dynamic "what if?" scenarios to be explored different potential topologies prior to anything actually being changed.
Even this isn't the difficult part - it's just software engineering and a bunch of algorithms most of which already exist in other disciplines.
The difficult part is creating an industry-wide set of commonly agreed base data that can be used to underpin the simulation model when applied to a particular organisation or business domain.
This isn't just gathering raw numbers, as the "Business Intelligence" people would have us do, but needs a detailed analysis of the variables that affect each of the metrics e.g. time delay per firewall in a network or record density in a database storage segment or asynchronous disk I/O response time and so on.
Unfortunately I can't see this bit happening any time soon because most companies wouldn't see where the payback would be in doing this.
Saturday, 23 October 2010
Tuesday, 21 September 2010
Data, Information & Knowledge - The Process of Learning
A key question that frequently arises in Data Architecture is: What is the difference between Data, Information and Knowledge?
It might seem an odd topic but understanding the “Process of Learning” is a key aspect of understanding the separation of these three classifications in order to create a true Knowledgebase rather than a mere Database.
Learning is a process involving a set of discrete states that the Learner (anyone who wants to discover new knowledge) passes through, and a set of activities carried out by the Leaner in order to move from one State Of Learning to another.
All learning starts from a position of ignorance and over time, through a structured process of gathering “data”; understanding it; and testing ideas, aims to gain knowledge about a given subject.
It may seem obvious but without a structured approach the results of the Learning Process are uncertain and, more importantly, critical knowledge required to fully understand the subject area may be missed or omitted entirely.
The Learning States and the activities for transforming from one state to another can be summarised as:
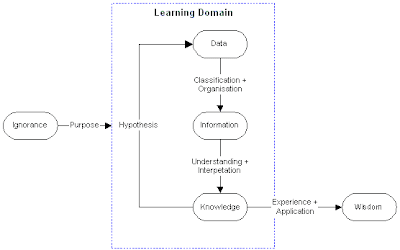
Each State indicates the relative position of a Learner with respect to a particular Learning Domain. The States that may exist are:
It might seem an odd topic but understanding the “Process of Learning” is a key aspect of understanding the separation of these three classifications in order to create a true Knowledgebase rather than a mere Database.
Learning is a process involving a set of discrete states that the Learner (anyone who wants to discover new knowledge) passes through, and a set of activities carried out by the Leaner in order to move from one State Of Learning to another.
All learning starts from a position of ignorance and over time, through a structured process of gathering “data”; understanding it; and testing ideas, aims to gain knowledge about a given subject.
It may seem obvious but without a structured approach the results of the Learning Process are uncertain and, more importantly, critical knowledge required to fully understand the subject area may be missed or omitted entirely.
The Learning States and the activities for transforming from one state to another can be summarised as:
Each State indicates the relative position of a Learner with respect to a particular Learning Domain. The States that may exist are:
- Ignorance is the state of not knowing something about a particular Learning Domain.
- Data is basic Learning State where the Learner possesses the raw and unformatted facts and observations that are available or may be collected within the Learning Domain.
- Information is the Learning State where the Learner can provide Information about what already exists within the Learning Domain and is able to retrieve that Information in an organised and structured manner. This is the “Body of Truth”
- Knowledge is the state that is achieved by having Information that is understood by the Learner. This includes all facts that can be systematically and verifiably derived from the underlying Information that forms the “body of truth” on which a particular degree of confidence can be placed.
- Wisdom is achieved when we can deduce or predict the likely answer to a question by recognising it’s similarity to other knowledge we possess without having to re-enter the Learning Domain from the beginning of the Learning Process.
Note: We could also argue that it’s the degree of assertion, ranging from "somwething I've recorded" through “something I believe” to “something I know”, representing the confidence level that the Leaner applies to the Facts that would classify it as Data or Infprmation or Knowledge.
In addition this body of Facts can include “incorrect” facts as well as “correct” facts because the fact that something is definitely not true is also may also be meaningful.
The transformations that take place are:
- “Purpose", given awareness of Ignorance, is the process of entering the Leaning domain. It’s formulating the objectives and goals that are set as the reason for learning. Without Purpose the Process of Learning is unfocussed and directionless. This could be regarded as a pre-condition to learning but, in the case of Human Learning, makes more sense to regard it as a transformation that prepares the Learner for the process of Learning.
- “Classification + Organisation” is the basic process of describing data by classifying the various data-items and organising them into data hierarchies.
This is the initial task because in order to extract Knowledge the Data must first be placed into a framework that is understandable and well structured. - “Understanding + Interpretation” constitute the analysis methods that are applied to the Information in order to extract Knowledge from the Information that is available.
- “Experience + Application” is the process of “testing” Knowledge by applying it outside of the Learning domain. A possible outcome of this transformation could be a failure of application and the need to re-enter the Learning domain i.e. "Something is wrong and we need to find out what."
- “Hypothesis” is the process of examining Knowledge to formulate questions that require additional Data to be subsumed into the Learning domain.
Of course, the Learning Process potentially forms an infinite loop because there is always at least one more Hypothesis that could be made. The exit condition is a lack of willingness or reason to hypothesize i.e. Purpose has been satisfied and the necessary Knowledge has been acquired.
In addition any individual element within the Learning Domain could be the subject of its own individual Learning Domain and any number of Learning Domains can be combined to form larger Learning Domains.
Of the three transformations within the Learning Domain the “Hypothesis” transformation is a “free thought” process that is very difficult to quantify in procedural terms, i.e. we don’t know enough about free-thought to be able emulate it in an artificial construct so this requires “real people” to formulate the questions that need to be answered.
The other two transformations can however be quantified and, much more importantly, can to a large extent be automated to produce a body of knowledge. That is:
- Data collected from outside the domain can be automatically classified and organised as it is integrated with existing Information already in the domain. Once ot conforms to the pre-defined data quality criteria and can be interrogated in a meaningful way then we have more Information.
- “Understanding + Interpretation” are provide by analytical functions that access the Information and derive Knowledge that is npot inherently apparent from the individual instances of Information.
- For example Average Building Energy Rating ratio requires two Facts (the Number of Buildings and Energy Rating for each Building) to calculate it and the result is not directly derivable from either Fact in isolation.
This is “Learning” in the pedagogical sense but it is “Learning” of the Intelligent rather than the Extelligent kind. That is, we may have much of the Knowledge freely available as Facts but in varying States of Learning and, from the perspective of a single person, it exists in many pockets of Knowledge distributed across many individual locations.
From the collective perspective, we want to move towards the Extelligent end of the spectrum with a common and shared understanding of the body of knowledge that transcends the existence of any individual information repository or any one persons knowledge of it.
It is the extelligent gathering together of knowledge into a single location to meet a common purpose that makes a Knowledgebase an important research and decision support tool for understanding one of the most critical and complex issues of our time.
Saturday, 21 August 2010
Is SOA of interest to a Data Architect?
This question came up recently on one of the forums I subscribe to and piqued my interest.
Whether Service Oriented Architecture (SOA) is specifically of interest to a Data Architect depends on what type of Data Architect you aspire to be.
There are at least dozen easily identifiable variations that all revolve around the definition and processing of data but require different skill-sets. However the main differentiating factor, for me, is whether the Data Architect is primarily interested in producing architectures for persistent data storage or transient data processing.
I do data processing but I know quite a few Data Architects that focus solely on designing and building databases and data centres for persistent storage but with little interest in what the data is or what it’s used for.
For this type of Data Architect it's all about infrastructure and technology , i.e. they are mainly interested in technical issues such as availability; backup & recovery; security; hardware performance and a bucket load of similar things to do with infrastructure and focussing on the stuff that is physically deployed to support the data repository.
For a Persistent Storage Data Architect I'd say that SOA, like pretty much any other secondary architectural framework, will add little benefit other than intellectual interest.
On the other hand, assuming it’s data processing type of Data Architecture that’s of interest, then it's important to establish the type of data processing environment that you're going to focus on e.g.:
For example, OLTP is "high volume / short transactions" but DSS is "low volume / long transaction" processing or Federated data requires two-phase commit but Centralised data doesn't.
Of course, if you’ve done any serious structured systems analysis (e.g. SSADM, OOA&D etc) then most Data Architects will probably have all the basic knowledge required to get by in a Service Oriented environment without too much effort because the art of Analysis & Design doesn’t significantly change no matter what is being deployed.
Whether Service Oriented Architecture (SOA) is specifically of interest to a Data Architect depends on what type of Data Architect you aspire to be.
There are at least dozen easily identifiable variations that all revolve around the definition and processing of data but require different skill-sets. However the main differentiating factor, for me, is whether the Data Architect is primarily interested in producing architectures for persistent data storage or transient data processing.
I do data processing but I know quite a few Data Architects that focus solely on designing and building databases and data centres for persistent storage but with little interest in what the data is or what it’s used for.
For this type of Data Architect it's all about infrastructure and technology , i.e. they are mainly interested in technical issues such as availability; backup & recovery; security; hardware performance and a bucket load of similar things to do with infrastructure and focussing on the stuff that is physically deployed to support the data repository.
For a Persistent Storage Data Architect I'd say that SOA, like pretty much any other secondary architectural framework, will add little benefit other than intellectual interest.
On the other hand, assuming it’s data processing type of Data Architecture that’s of interest, then it's important to establish the type of data processing environment that you're going to focus on e.g.:
- What type of activity profile is required? Is it predominantly:
- On-Line Transaction Processing (OLTP), typically characterised by high-volume short duration activities, such as a retail operation or financial markets trading.
- Decision Support (DSS or BI) focussing on analysis and reporting against historic information.
- Data Warehousing focussing on the long-term archiving of masses of company information for posterity.
- What type of process distribution is being supported i.e. is it:
- A "Centralised" environment where each business activity is executed against a single centralised data repository.
- A "Federated" environment where a single Business Activity potentially draws information from multiple physically separated sources and merges them together in order to carry out the activity.
- A "Distributed" environment where the multiple implementations of the same Business Activity may be executed in a number of different venues based on some external constraint such as geographic location or line of business.
For example, OLTP is "high volume / short transactions" but DSS is "low volume / long transaction" processing or Federated data requires two-phase commit but Centralised data doesn't.
Now if we look at the underlying principles of Service Orientation then I'd say that SOA really only lends itself to OLTP and Federated / Distributed data processing environments (which is where all the fun really is) and, if that is the type of data processing environment you're trying to design then an understanding of Service-Orientation (if not SOA itself) is essential.
For SOA the key principles that are very, very important include:
- Location Independent - i.e. the relationship between client and service are irrelevant),
- Stateless - the Service Provider has no memory of any previous invocations of the Service and once completed (either successfully or otherwise) the previous state of the data environment is discarded. In other words all Services are single-phase commit and do not wait for separate acknowledgement from the Service User.
- Idempotent - a Service can be called repeatedly without side effect for any previous or subsequent invocation.
- Loosely coupled - the Service User only uses the parts of a Service that it needs and ignores everything else.
- Dynamic - the characteristics of the Service being called can change between service calls and it is the Service Users responsibility to maintain compatibility with the Service Provider.
Of course, if you’ve done any serious structured systems analysis (e.g. SSADM, OOA&D etc) then most Data Architects will probably have all the basic knowledge required to get by in a Service Oriented environment without too much effort because the art of Analysis & Design doesn’t significantly change no matter what is being deployed.
Wednesday, 11 August 2010
"The Earth Is Flat" and "The Meanings of Meaning"
To a great extent Enterprise Data Architecture is a philosophical activity in that much effort is spent in defining terms and concepts and discussing what they mean rather than just engaging in physical activity.
No matter how much we try personal preferences experience will always creep into any proposed architecture or data model along with undocumented assumptions that "go without saying because everyone accepts them" and ill-defined terms whose "meaning is already known to everyone".
Personal preference based on past experience cannot be avoided (nor should it!) because past experience is after all why we are paid to do the job and any underlying assumptions, which are generally a direct result of experience, can only be documented as they are discovered through conversation with others.
It is the last point of "meaning is already known to everyone" that is the tricky bit as it involves understanding the importance of "The Meanings of Meaning" which is one of most important concepts in understanding and documenting knowledge as it underpins much of the science of semantic analysis.
The "Meanings of Meaning" states that every communication between two parties has three distinct meanings:
- The meaning that the party making the statement had in mind when they made the statement which is distorted by their own imperfect knowledge of the domain being discussed - the "Writers Meaning".
- The meaning that the party reading the statement applies to it based on their equally imperfect but different knowledge of the domain - the "Readers Meaning".
- What the statement actually means based on perfect knowledge of the domain and the context in which it is used - the "Contextual Meaning".
These three meanings are often different but most people assume that they are the same.
We frequently read articles and documentation that that use well known terms without actually providing any definition of what the term means in the context of the article. It's generally assumed by the writer that the reader will know what is meant by a particular term and that the Reader's Meaning will be the same as the Writer's Meaning.In general conversation it can be even more confusing. I could, for example make a statement such as "The Earth Is Flat" which may be true or false depending on the context in which it is made.
If I was talking about the planet in general then most people (but not all!) would regard this as incorrect (which might be the politest of responses) because the planet Earth is provably spherical.
However if a was a farmer in Kansas (US) or Norfolk (UK) looking out over a newly ploughed field then the earth (the soil) might indeed look flat as far as I can see. Another farmer standing next to me might easily agree that the earth was indeed flat and even congratulate me on a job well done.
So, to fully understanding the meaning of the statement "The Earth Is Flat" I have to know the context in which it was made, what was being discussed and who was part of the discussion.
In fact, when it comes to understanding the Meanings of Meaning context is everything and something that a Data Architect needs to be very aware of in order to avoid the misunderstandings that result from applying ones own meaning to a statement and failing to explore what the actual meaning was.
If we put our minds to it we can all probably come up with hundreds of examples of misunderstandings that occurred because two different people used the same label (Noun) to mean different things e.g. when Sales and Finance talk about a Customer they are almost certainly talking about completely different things even though the Sales type of Customer might eventually become the Finance type of Customer.
Most experienced Business Analysts and Data Modellers inherently know this principle but rarely state it - it's an undocumented assumption - but is sometimes worth mentioning to the business stakeholders as an explanation as to why we keep asking them tedious and highly detailed questions about trivial things they have told us.
Tuesday, 10 August 2010
Principles, Patterns, Policies & Processes
A question that I am regularly asked is "What is the difference between Architecture and Design?" which is one of those imponderable questions that is often the subject of great debate within the Information Technology community (though mostly down the pub).
Usually this ends up as a compare and contrast type of debate with conjectures such as:

Usually this ends up as a compare and contrast type of debate with conjectures such as:
- Architecture is about "What" and Design is about "How"
- Architecture is Objective and Design is Subjective.
- Architecture is Conceptual and Design is Physical
- Architecture is about Requirements and Design is about Solutions.
- Architecture is Platform Independent and Design is Platform Specific
- ...add for personal favourite
- Architectural Patterns, as per their close sibling the Design Patterns, is any type of model, template, or artifact that describes a generic problem and the potential characteristics of any solution. The intent of a pattern is simply to capture the essence of a generic solution in a form that can be easily communicated to those who need the knowledge.
- Architectural Principles define key characteristics for the design and deployment of the resulting systems.
The Patterns are both abstract and concrete at the same time. They are Abstract in the sense that they describe a generic solution to a generic problem in generic terms but Concrete in that they can be directly applied to a particular instance of a problem to construct a definite solution.
They are also reusable and can be applied many times to other problems of a similar nature where, even if not directly applicable a Pattern can still indicate the general shape of another derived pattern e.g. the “Powered Vehicle” indicates the general structure of a Car, Lorry, Aeroplane, Train etc but may need extending or modifying to deal with the specifics of each.
- Policies are the non-negotiable constraints that the business itself will apply to any systems or applications that need to be developed. They are really constraints on the Architect (who may not get any input into defining them) as well as the Development team.
- These will cover things like technology decisions, programming languages, application availability requirements, disaster recovery, testing requirements and anything else that the business decides is an operational requirement
- Processes cover the mechanisms that will be used to govern the Development with respect to the Architecture including activities such as Design Reviews, Change Management, Divergence & Convergence and so on.
- The Governance Processes are most likely to be tailored specifically to the organisation according to the development environment and how it like to manage things. However it is important to emphasise that the the Development activity should conform to the Architectural requirements NOT the other way round.
When brought together into a single coherent Architectural Framework the 4P's provide the tools necessary to ensure that any implemented systems meet desired "quality" criteria without, hopefully, being too prescriptive in how the target systems will actually be designed and built.
Given that the production of Architecture is really just focused on the production of a framework, the main involvement with Systems Development is in governance and, because we all like a diagram whenever possible, fits together like this:
An important point, at a bit of a tangent, is that Architecture is not about Task & Resource Management which is a function of Project / Program Management and, given that there a quite a number of well established methodologies for managing that activity, is not something that I think an architecture needs to consider.
So there we have it - the above is what I see as Architecture and everything else, including physical Design, is part of Development.
That doesn't mean to say the one person cannot carry out both Architecture and Design roles but it's nice sometimes to define where the boundary of responsibility lies.
Monday, 9 August 2010
Using a Fact Model to verify a Data Model
One of the main problems with verifying that a structured data model correctly defines the facts that have been provided by the Subject Matter Experts (SME) about the business is that frequently the modelling notation, whether UML, ERD, ORM or XSD, may be unfamiliar to the SME so they are unsure about what exactly is being said. Even when the basic concepts of a data model are explained there is still concern that the SME might misinterpret the model and sign-off something that is actually incorrect.

Often these mistakes will result in additional downstream cost once the mistake is discovered and remedial work is carried out. To avoid ambiguity or misunderstandings it can be useful to use a Fact Model to express the facts in "natural language" so that they can be read as a set of individual statements that are more easily comprehended and individually verified by the SME.
For example, take the following model fragment (in the UML notation):
An experienced data modeller or software developer would quickly identify the following facts (amongst others):
- A Consolidated Account is a type of Sales Account.
- A Customer Account is a type of Sales Account.
- A Consolidated Account aggregates one or more Sales Accounts.
- A Sales Account must have a Registered Address which is a valid Address.
- A Sales Account must have an Account Number which is a valid Account Number.
- A Sales Account may have a Credit Limit …
- A Sales Invoice must be Posted To one and only one Customer Account.
- ...and so on
As a set of definitive atomic statements I think it is much easier for the SME to review each of these facts and confirm whether it is correct or not and, if it isn't correct, amend it.
Facts can also be used to explain or elaborate less obvious features of a model, such as rules captured as constraints on a Class, Attribute or Relationship. For example, all of these facts are in the model but not part of the diagrammatic representation:
Facts can also be used to explain or elaborate less obvious features of a model, such as rules captured as constraints on a Class, Attribute or Relationship. For example, all of these facts are in the model but not part of the diagrammatic representation:
- An Address must have a Building Number or Building Name.
- An Account Number is a numeric string of exactly six digits
- A Customer Name is an alphanumeric string up to 40 characters in length.
- ...and so on
OK it can be a bit tedious pouring over 1000's of statements but with a complex data model there are a lot of benefits to breaking down the model this way when it needs to be verified with the business stakeholders, some of which are:
- Each fact is expressed atomically, i.e. cannot be reduced to even simpler facts, so reviewed independently of any other fact.
- Being a "natural language" the reader has better comprehension of what each fact is actually stating.
- The Fact Model can be distributed as a text document to multiple recipients who can read and amend it without requiring access to the modelling software used to create the original model.
Not so long ago producing a Fact Model was a standard feature of most data modelling software (and is still a part of some such as Oracle Designer) but seems to have fallen out of fashion with the newer modelling languages such as UML and XSD.
However, if there is a lot of formal data modelling being performed then a Fact Model can be very useful and well worth investing the time to create an appropriate language (or using one of the established languages such as NORML or SBVR) and reporting capability.
Subscribe to:
Posts (Atom)